
K- Means: Clustering de acciones
Para continuar con el artículo anterior sobre K-Means, hoy quería ver un lado un poco más práctico. La idea es utilizar minería de datos aplicada a un problema de diversificación y agrupación sectorial de las acciones (no me olvido que en este blog se habla sobre inversión y trading cuantitativo, así que intento no perder demasiado el foco).
En este artículo, como técnica de clustering, utilizaremos el algoritmo K-Means con Python.
Comenzamos:
La clasificación de acciones por sectores
La clasificación tradicional de las acciones es por sectores industriales. De esta forma, aquellas empresas que realizan actividades económicas similares se agrupan dentro de un mismo sector, industria y sub-industria.
El estándar de clasificación más conocido es el GICS (Global Industry Classification Standard) y es el que utilizaremos como comparativa en nuestro análisis. La siguiente tabla muestra los sectores GICS:
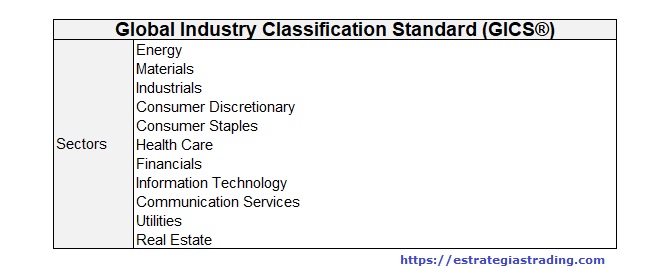
¿Cómo utilizan los inversores estos sectores?
De varias maneras. Por ejemplo, si nos orientamos al largo plazo, una de las formas más tradicionales de diversificar una cartera de acciones es invirtiendo en varias acciones pertenecientes a distintos sectores. Otros inversores pueden estar más interesados en aplicar la teoría de los ciclos económicos e ir rotando la cartera entre acciones cíclicas y defensivas o utilizar los sectores para construir carteras temáticas. Otros utilizan los sectores porque aplican el método Weinstein.
Sin embargo, todos esos usos de los sectores se basan sobre las mismas premisas:
– Suponemos que las acciones del mismo sector se comportan (en general) de la misma manera.
– El GICS puede clasificar de una manera precisa a una empresa dentro de un sector (no hay ambivalencia, una acción no puede pertenecer a más de un sector al mismo tiempo aunque la actividad económica de la empresa sea diversa).
Un enfoque alternativo a la clasificación por sectores
Y aquí viene mi duda sobre esta manera de agrupar las acciones. ¿Esta clasificación tradicional por sectores puede definir la similitud entre las acciones o empresas que cotizan en bolsa?
En mi opinión, si bien esta clasificación por sectores puede ser útil para diversificar una cartera, para un inversor lo que de verdad define la similitud entre las acciones es su evolución en bolsa.
La idea de este artículo es testear un enfoque alternativo con Data Mining y agrupar las acciones según su rendimiento y volatilidad utilizando el método de clustering K-Means. El clustering es un método de aprendizaje no supervisado que intenta dividir los datos en grupos separados. El resultado deseado de la agrupación es asegurar que las observaciones dentro de los grupos sean similares entre sí pero diferentes a las observaciones en otros grupos.
Análisis
Notas previas:
La información sobre la clasificación por sectores la obtengo desde Wikipedia y los datos de cotizaciones son de YahooFinance. No estoy teniendo en cuenta las acciones deslistadas. Este ejercicio es simplemente una prueba de concepto para aplicar K-Means y no divido los datos en train/ test set
Para aquellos que quieran ver más detalles. Al final del artículo dejo un enlace a al notebook de Jupyter.
Comencemos primero dando un vistazo a la situación inicial.
Podemos ver un gráfico de dispersión que muestra la rentabilidad diaria media de cada una de las acciones que integran del SP500 relacionada con su volatilidad.
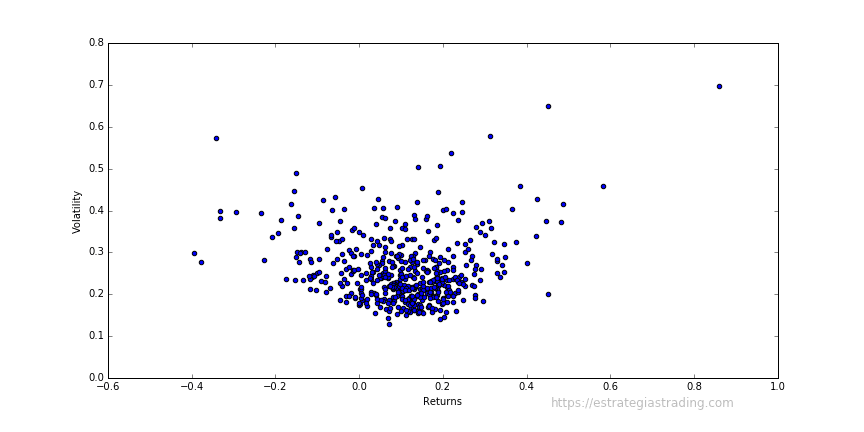
A primera vista, parece que los datos no se juntan en grupos (que voy a llamar clústers a partir de ahora) predefinidos.
Ahora vamos a ver esta misma información pero marcada según el sector al que cada acción pertenece.
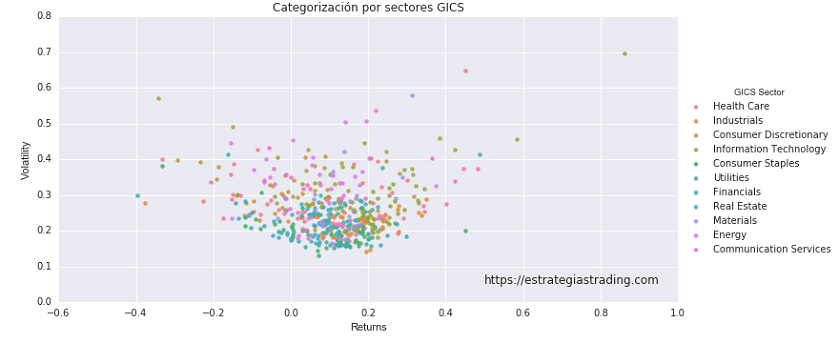
En la imagen puedes ver el mismo gráfico de dispersión pero con los sectores representados por colores. Aunque hay zonas donde un color es dominante, no todas las acciones de un mismo sector no están agrupadas de una forma definida. Hay sectores donde las acciones están más dispersas.
Lo podremos ver mejor si dividimos este gráfico en los 11 sectores.
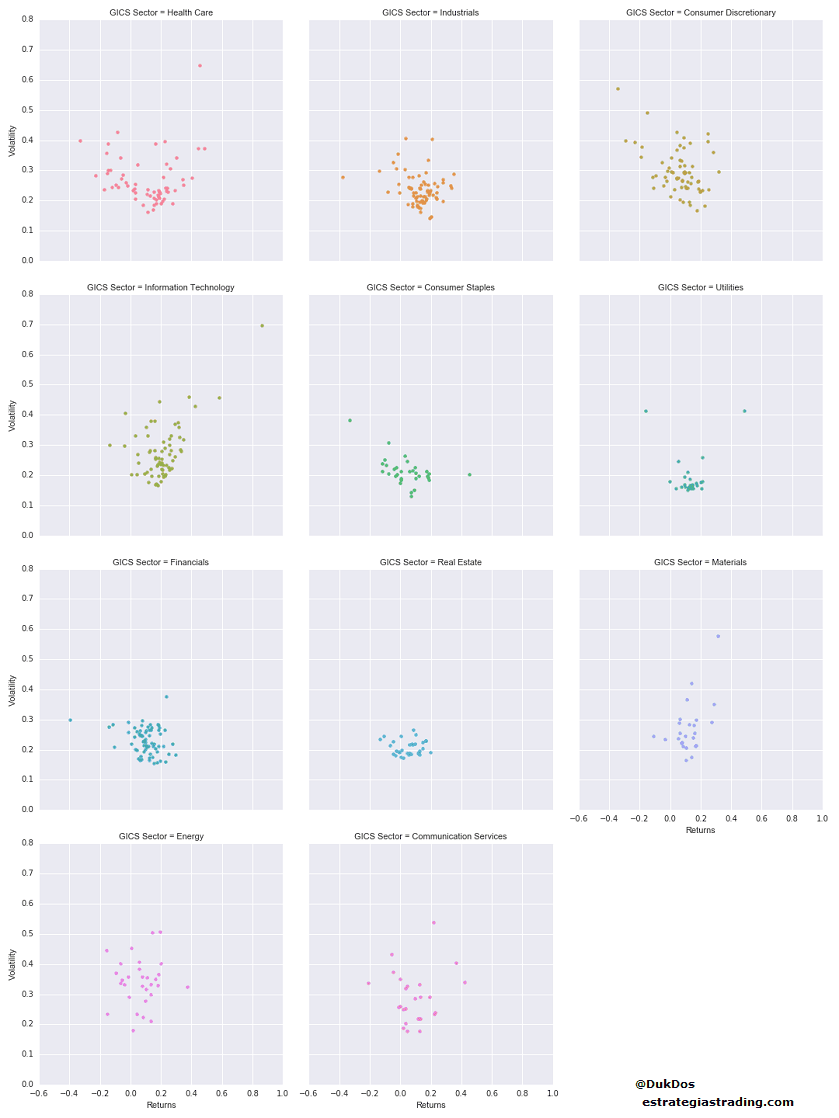
Como ejemplo y contra ejemplo tenemos Real State y Health Care. En el sector de Real State todas las acciones tienen un comportamiento medio similar. Las acciones del sector Health Care tienen un comportamiento medio bastante dispar.
Algoritmo K-Means con Python
Ok, vamos al tema y a la misma serie de datos le aplicamos el algortimo K-Means.
Para esto previamente tenemos que re-escalar los datos y definir el número de clústers.
La elección del número de clústers es el punto clave de este algoritmo. Si revisamos la teoría podremos ver que existen varios métodos para seleccionar el número óptimo de clústers. Aquí testeamos el «método del codo» donde la calidad del agrupamiento se mide con la inercia. Para decidir el número de clústers tenemos que tener en cuenta que si escogemos muy pocos clústers podemos llegar a agrupar datos demasiado heterogéneos, pero si hacemos demasiados estaremos perdiendo la verdadera función del clustering al agrupar datos similares en clústers diferentes.
En este caso utilizo StandardScaler del paquete Scikit-Learn para estandarizar los datos y agrupo en 4 clústers.
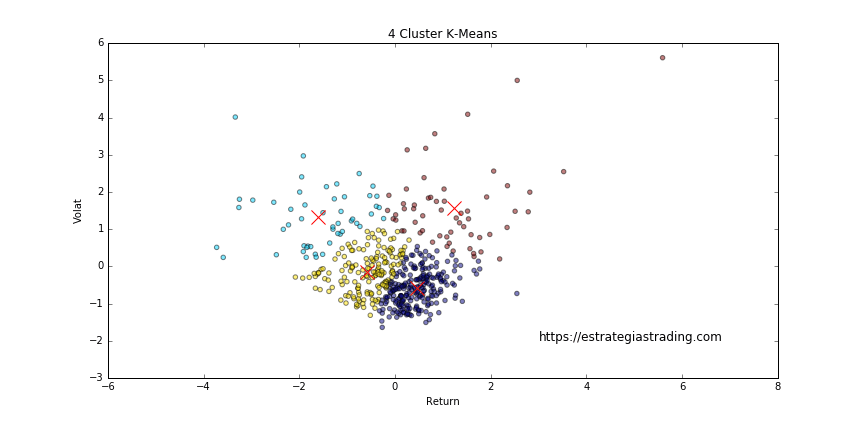
Al igual que antes estamos viendo un gráfico de dispersión con la rentabilidad media y volatilidad de las acciones que integran el SP500. El algoritmo K-Means agrupa los datos en 4 clústers (los puedes ver según los distintos colores). Cada clúster tiene un centroide (son las cruces rojas) alrededor del cual se agrupan los datos.
De una forma intuitiva podemos interpretar que un clúster corresponde a las acciones con mayor volatilidad y rendimiento, otro clúster a las acciones con mayor volatilidad pero rendimiento menor a cero, otro a las acciones menos volátiles pero aún con bajo rendimiento y por último a las acciones menos volátiles y con rendimiento positivo.
Es mucho más fácil de ver si hacemos plots individuales:
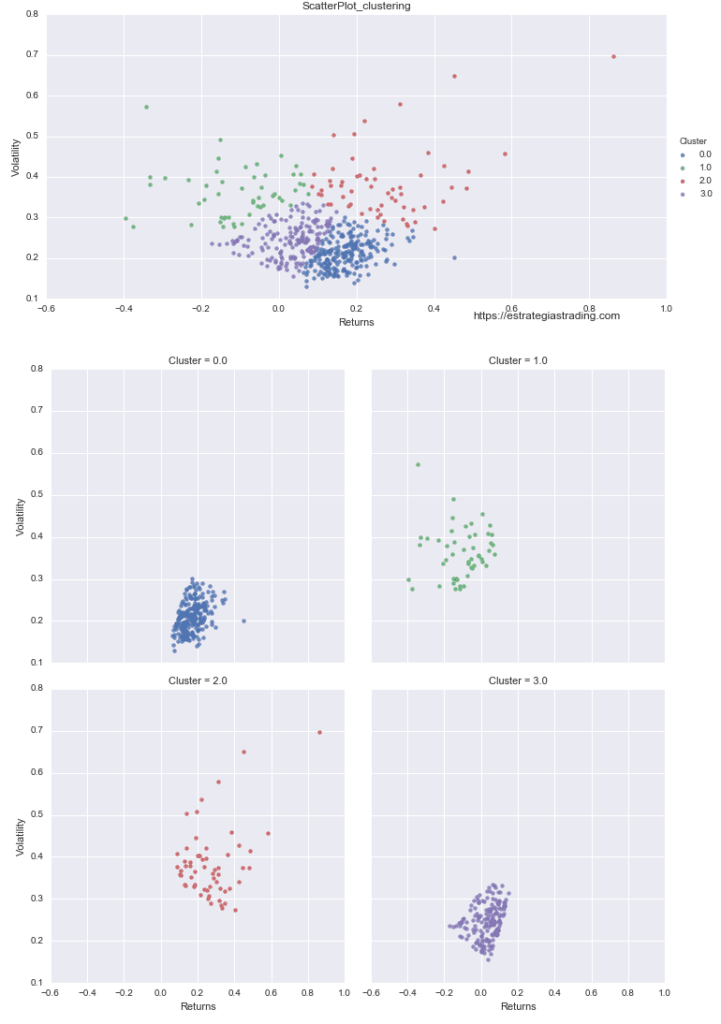
Cuatro clústers es un agrupamiento que me parece útil. ¿Qué pasaría si aplico el algoritmo K-Means con 11 clústers para tener el mismo número de clústers que tenía con el agrupamiento en sectores?
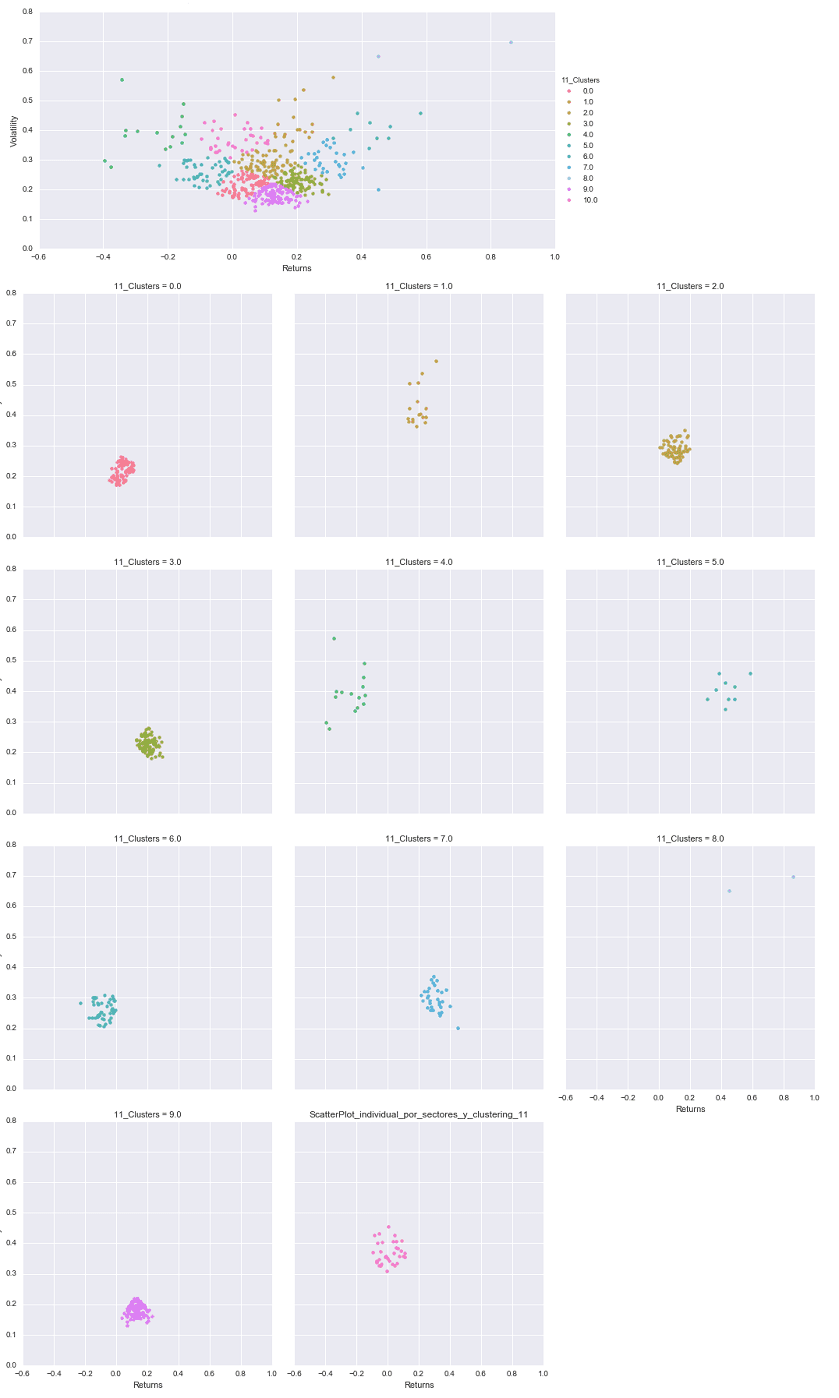
Pues que tengo una segmentación excesiva y tengo demasiados clústers. Por ejemplo el clúster número 8 tiene tan solo dos acciones.
Como hemos visto, K-Means es un algortimo de clustering bastante bueno, pero como todo tiene algunas desventajas. La principal es que nos obliga a determinar de antemano el número de clústers y si no elegimos correctamente esto, los resultados se verán afectados.
Para saber más:
- Más información sobre la clasificación en sectores GICS : https://en.wikipedia.org/wiki/Global_Industry_Classification_Standard
- Si quieres ver más detalles sobre los datos, cálculos y demás extras: este es el link a Github donde he compartido el notebok de Jupyter: https://github.com/Duk2/Analisis_con_Python/blob/master/K-Means.ipynb


3 comentarios en «Acciones del SP500 por sectores – Ejemplo de K-Means con Python»