
Algoritmo de clustering jerárquico
El Clustering Jerárquico (agrupamiento jerárquico o Hierarchical Clustering en inglés), es un método de data mining para agrupar datos (en minería de datos a estos grupos de datos se les llama clústers).
El algortimo de clúster jerárquico agrupa los datos basándose en la distancia entre cada uno y buscando que los datos que están dentro de un clúster sean los más similares entre sí.
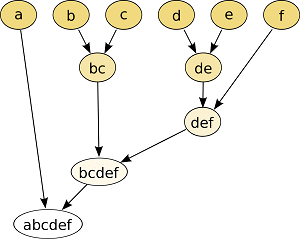
En una representación gráfica los elementos quedan anidados en jerarquías con forma de árbol.
Lo mejor para explicarlo es una imagen. Así que para ilustrar mejor este tema de agrupación en categorías voy a retomar un ejemplo gráfico muy difundido – y a la vez es el más descriptivo que he encontrado – que es el que exponen en la Wikipedia.
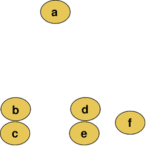
En la primera imagen vemos cómo están distribuidos los datos y a qué distancia se encuentran unos de otros. En la segunda, vemos un ejemplo de clustering jerárquico dónde los datos se agrupan en función de la distancia (en este caso distancia euclidiana) entre ellos.
Al igual que el método de K-Means (aquí puedes ver una introducción al método K-Means publicada en esta web), los algoritmos de agrupamiento jerárquico están dentro de la categoría de algoritmos de aprendizaje no supervisado.

