

Hola. El artículo de hoy tiene dos objetivos:
Por un lado, examinar la correlación (o la no correlación, ya lo veremos luego) entre el oro y la bolsa. Veremos también si el oro es un buen valor refugio para tiempos de bolsas bajistas.
Por otro lado, continuar con el análisis de series temporales, esta vez con ejemplos simples de estadística con Python.
Allá vamos …
Estadística con Python: Examinar datos
Para el análisis voy a utilizar dos ETFs y descargar los datos desde YahooFinance.
GLD – SPDR Gold Trust
SPY – SPDR S&P 500 ETF Trust
Fechas entre 1/1/2005 ( fecha inicial de GLD) y 1/11/2016.
He elegido hacer el análisis utilizando ETFs porque prefiero privilegiar activos con los que luego pueda operar con mi broker.
Gráfico: Oro – Bolsa
Comenzaremos mirando la evolución de las cotizaciones de GLD y SPY en un gráfico utilizando matplotlib.
plt.figure(figsize=(16,8)) spy['Adj Close'].plot() gld.Close.plot() plt.title ('evolución diaria de precios') plt.ylabel('precios') plt.legend(['SPY','GLD'], loc = 0)
#Nota: Para SPY tomo Adj Close para ajustar el impacto de los dividendos
Podemos observar que hay periodos donde ambos ETFs parecen mostrar la misma tendencia y otros donde su tendencia es claramente opuesta.
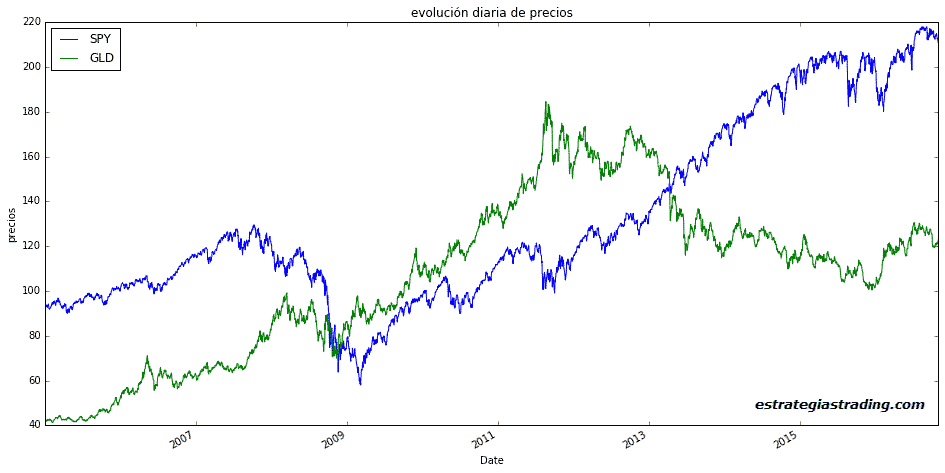
Bueno, vamos a ver esto con un poco más de detalle.
Análisis de la rentabilidad
Seguimos por un poco de estadística descriptiva.
Si calculamos la rentabilidad semanal de cada ETF, podemos ver que su rentabilidad logarítmica media es casi cero:
media_log_sem = (GLD_sem.Log_Ret.mean(),SPY_sem.Log_Ret.mean()) media_log_sem
(0.0017441394251161261, 0.001321775999586396)
Pero… ¿es una rentabilidad estable? Qué podemos ver si estudiamos su distribución en un histograma:
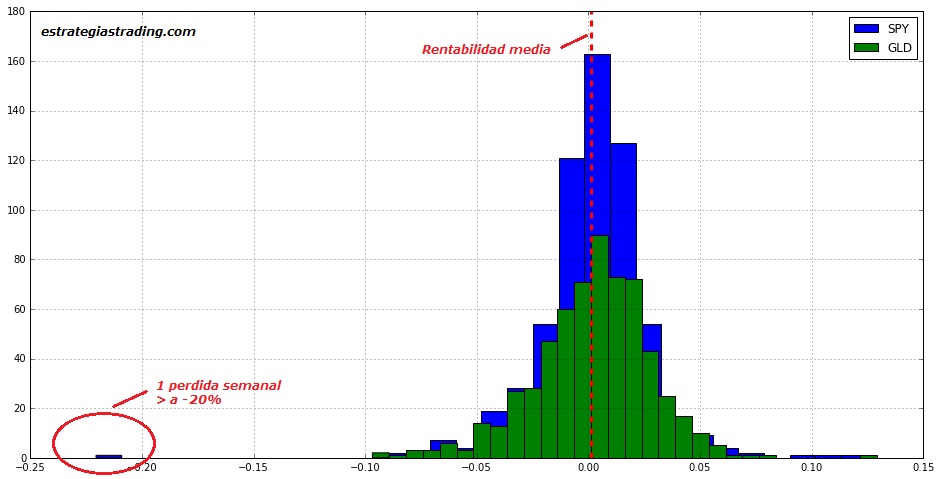
A primera vista parece ser una distribución bastante equilibrada. El valor negativo más extremo corresponde a una pérdida superior al 20% semanal de la semana del 5/10/2008.
#Busco cuando ha sucedido la pérdida semanal superior a 20% SPY_sem.loc[SPY_sem['Log_Ret'] < -0.2]
La desviación estándar para todo el período
#desviación estándar (SPY_sem.Log_Ret.std(),GLD_sem.Log_Ret.std()) (0.024847103484906666, 0.02601512395699718)
Comparativa con una distribución normal
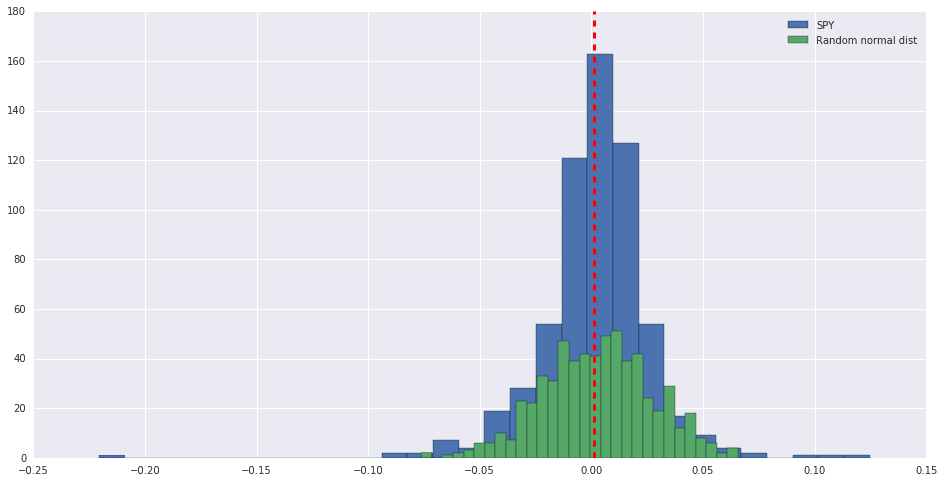
Antes decía que la distribución en el histograma parece equilibrada. Pero dista mucho de parecerse a una distribución normal.
Por ejemplo, para verlo en un gráfico podemos intentar esto: Tomamos los valores de media y desviación estándar de SPY y los graficamos como distribución normal.
SPY_sem.Log_Ret.hist(bins=30,figsize =(16,8)) plt.hist(np.random.normal(np.mean(SPY_sem.Log_Ret), np.std(SPY_sem.Log_Ret),len(SPY_sem.Log_Ret)),bins=30) plt.legend(['SPY','Random normal dist'], loc = 0) plt.axvline(SPY_sem.Log_Ret.mean(), color='r',linestyle='dashed', linewidth=3); #Nota: cada vez que ejecutes el grafico, se generará una nueva serie de datos para representar la distribución normal.
Relación oro y bolsa
Me parece que casi todos hemos oído alguna vez que «el oro actúa como valor refugio ante la caída de las bolsas».
Bien, en teoría esta afirmación puede llevarnos a pensar que el oro y el SP500 tienen una correlación negativa. Simplificando un poco: pensaríamos que cuando uno sube el otro baja, verdad?
¿Pero qué pasa si intentamos verificar esta afirmación?
SPY_sem.Log_Ret.corr(GLD_sem.Log_Ret) 0.0066021494325757338
La correlación lineal entre los rendimientos semanales de GLD y SPY es prácticamente igual a cero.
Visualizar la correlación
¿Dónde está la correlación negativa potencial? A ver si la vemos en un gráfico de dispersión…
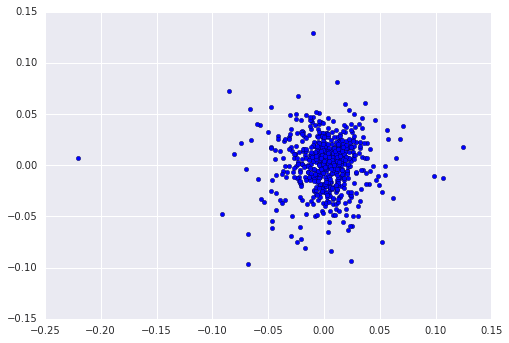
No…parece que tampoco.
Podemos pensar que la correlación es nula, pero sin embargo intuitivamente seguimos creyendo que hay periodos de alta correlación.
¿Qué tal si miramos cómo evoluciona la correlación a lo largo del tiempo?
Correlación: promedio móvil
Calculamos la correlación utilizando ventanas móviles de 20 semanas.
SPY_sem.rolling(20).corr(GLD_sem)['Log_Ret'].plot(figsize=(16,8)) plt.hlines(0,start,end, color= 'r') plt.legend(['Correlación 20 semanas'], loc = 0)
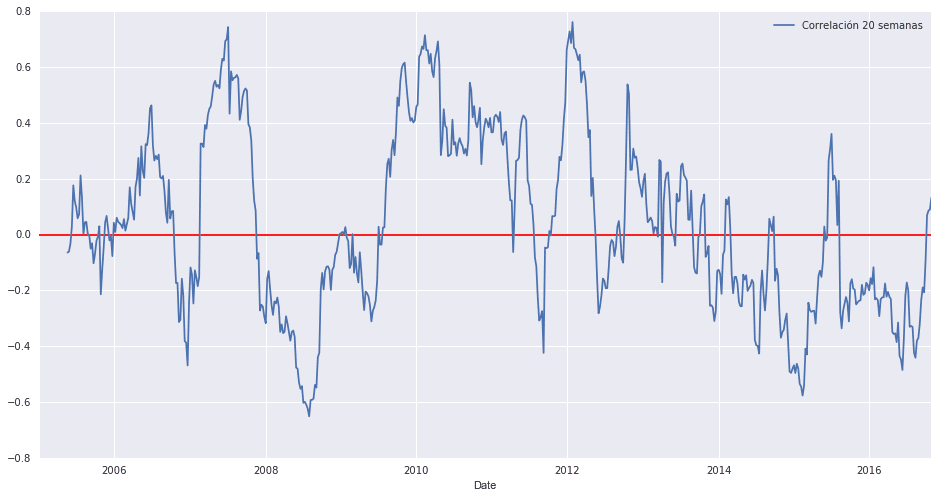
Podemos ver como oscila entre una correlación claramente positiva ( llegando casi a +0.8) y un coeficiente de correlación negativo.
Por último, cuando dibujamos en un gráfico las medias móviles del SPY y GLD conjuntamente con la variación en su rentabilidad y correlación:
fig, axes = plt.subplots(nrows=3, ncols = 1, figsize = (20,15)) axes[0].plot(SPY_sem['Adj Close'].rolling (window = 20).mean()) axes[0].plot(GLD_sem['Close'].rolling (window = 20).mean()) axes[0].set_title('SPY-GLD') axes[0].legend(['SPY- Media móvil 20 semanas','GLD- Media móvil 20 semanas'], loc = 0) axes[1].plot(SPY_sem.Log_Ret.rolling (window = 20).mean()) axes[1].plot(GLD_sem.Log_Ret.rolling (window = 20).mean()) axes[1].hlines(0,start,end, color= 'r') axes[1].legend(['SPY.Log Ret 20 semanas','GLD.Log Ret 20 semanas'], loc = 0) axes[2].plot(SPY_sem.rolling(20).corr(GLD_sem)['Log_Ret']) axes[2].hlines(0,start,end, color= 'r') axes[2].legend(['Rolling correlation. 20 semanas'],loc = 0)
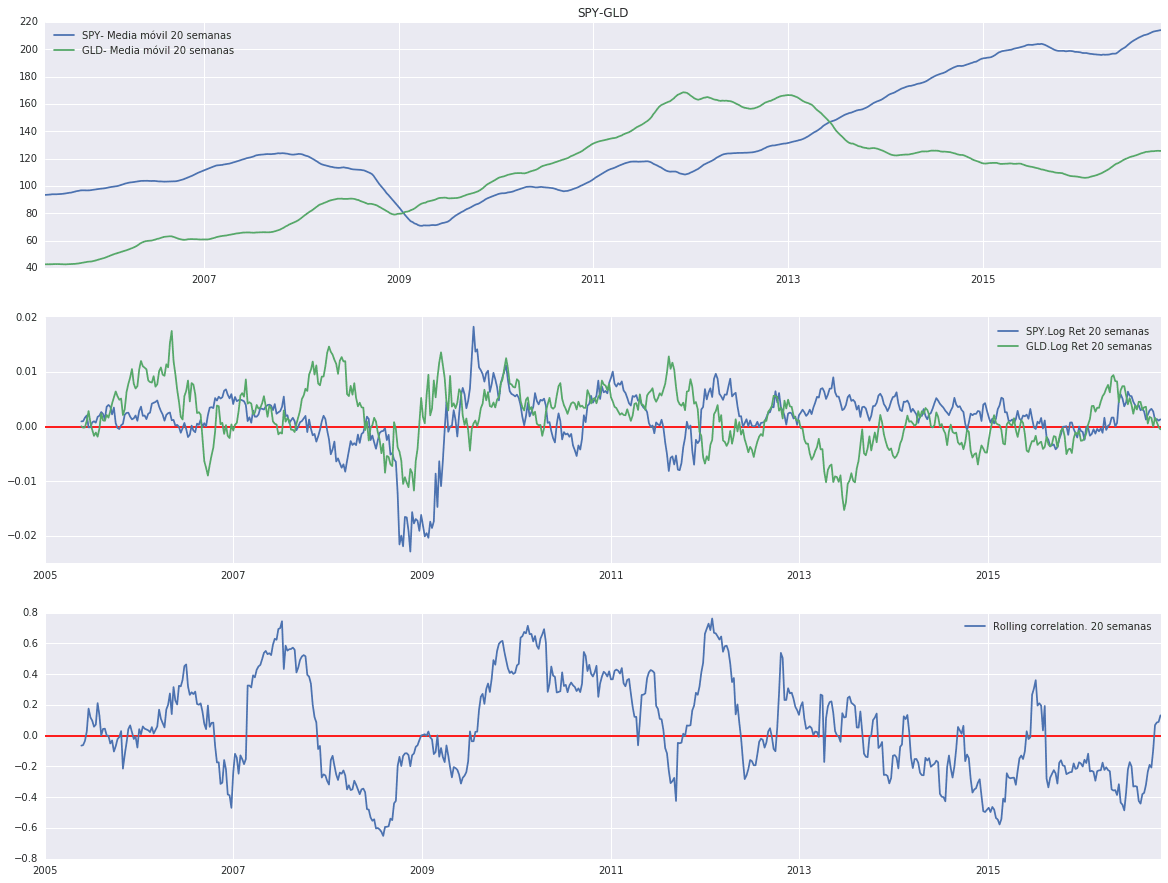
Finalmente: ¿Qué es un valor refugio?
Si nos guiamos por esta traducción casera desde Investopedia podemos ver que:
«Un valor refugio ( «safe haven» en su caso) es un activo que normalmente retiene su valor, o incluso lo aumenta, en tiempos de turbulencia en el mercado. Sin embargo, debido a que las condiciones del mercado son variables, aquellos valores considerados refugio también varían . Lo que parecía funcionar como valor refugio durante un periodo bajista del mercado, puede no funcionar como inversión segura durante otro periodo bajista».
Estoy aprendiendo poco a poco a manejarme con Python y especialmente con Pandas. Si quieres ver el notebook de Python que he utilizado para este post, lo puedes encontrar en este enlace de GitHub. Si prefieres realizar tu análisis con cualquier otro valor, es muy sencillo modificarlo cambiando los tickers.


No paras Duk2, en horabuena!!!
Ya nos contarás si crees que merece la pena las horas de aprendizaje en Python.
¿Cual es el periodo que has utilizado para el cálculo de la correlación?
Lo que se desprende de tu artículo es que ¿el oro no es un valor refugio?
Saludos.
Hola Ramón,
El periodo es entre 1/1/2005 ( fecha inicial de GLD) y 1/11/2016. ( Lo había apuentado en GitHub pero habia olvidado apuntarlo en el artículo, ahora lo corrijo).
Si el oro es o no un valor refugio: para este periodo yo no he encontrado correlación lineal entre la rentabilidad del oro y la rentabilida del sp500. Se podría hacer una prueba utilizando índices o futuros y buscando más atrás en las fechas. Pero, la dinámica del mercado no es siempre igual, y utilizar datos de los años 70, por ejemplo, no creo que aporte nada ( estoy estudiando times frames diarios y semanales).
Sobre Python: de momento estoy aprendiendo ( creo que en esto nunca terminamos de aprender cosas, verdad?)
Un saludo,
Gracias Duk2.
El día que dejemos de aprender cosas nos desplumarán.
Saludos.
Excelente artículo, Duk2.
Me gusta el planteamiento tipo ‘Mithbuster’ con un análisis totalmente reproducirle. Especialmente el que hayas usado Python y Pandas para ello, compartiendo fichero Jupyter. Ya que yo mismo he comenzado ha usar tambien Python para este tipo de análisis no hace mucho.
Después de probar anteriormente con Octave y R, finalmente me quedo con Python por la cantidad de herramientas que permiten un rápido desarrollo para analizar series temporales, hacer backtesting y poner sistemas en funcionamiento.
Si tienes un rato échale un vistazo a este paquete de backtesting, una madura alternativa a Zipline, que he comenzado a utilizar con buenos resultados : https://www.backtrader.com/
Un consejo para futuros artículos con archivos Jupyter, utiliza random.seed() de esta forma los resultados aleatorios (como la distribución normal) ejecutados en local serán los mismos que los que tu publiques en el articulo, aportando mas coherencia.
Un saludo.
Hola y gracias por tu comentario,
Yo también he estado mirando un poco R, sobretodo porque muchos de los análisis sobre series financieras están en R, pero creo que finalmente utilizaré Python.
Mirare el link que me envías.
Gracias por el consejo sobre random.seed(), no sabía que podía fijar la distribución aleatoria.
Un saludo,
Por si os fuera de utilidad: http://www.backtrader.com/blog/posts/2016-12-13-gold-vs-sp500/gold-vs-sp500.html
Buen articulo!
Me ha parecido muy interesante tu planteamiento sobre el aprendizaje de Python pues no sabia que podría ser tan útil en el tema de las inversiones.
Gracias por la información.
Saludos!
Gracias por tu comentario Juan Pablo.
Muy buen ejemplo, gracias por el aporte
Tienes algo armado para comparar portafolios?
Me facilitaría mucho la busqueda